Swiggy is India’s largest hyperlocal food and grocery delivery platform, which enables restaurants to sell their food online and deliver orders to the doorstep of the customer. It serves more than 40 million customers, with peak order processing of more than 3 million orders per second.
Apart from food delivery, it also serves the following business cases:
It enables customers to buy groceries, which get delivered in 2 to 5 minutes
It enables cloud kitchens to sell dishes online.
It delivers packages from one source to a destination anywhere in India.
I worked as a founding member of the Technical Program Management Organization, with a mandate to build a team that bridges gaps between multiple engineering, operational, and business teams. With the goal of faster product and feature development, refining and provisioning new tech components to scale the business, ensuring effective team management, improving the quality of delivery, enhancing the speed of execution, and bringing uniformity and standardization to technology platforms.
The Swiggy engineering organization was composed of multiple pods, some of which included restaurants, vendors, customers, delivery management systems, finance and accounting systems, DE tracking systems, payment systems, operations, and customer care. These teams were composed of various members, including product managers, marketing and sales teams, engineers, and testing team members. Due to the complexity of the platform and changing business requirements, we were facing challenges in coordination, communication, quality, and speed of execution within the engineering vertical and across other verticals. Teams were adopting different tech components and standards without a central authority.
As the head of the Technical Program Management team, I introduced a new tech governing body comprised of senior tech architects, which had the mandate of reviewing the tech stack across all pods, defining and enforcing tech platform standards and guidelines, and mandating TRMs and
Daily :
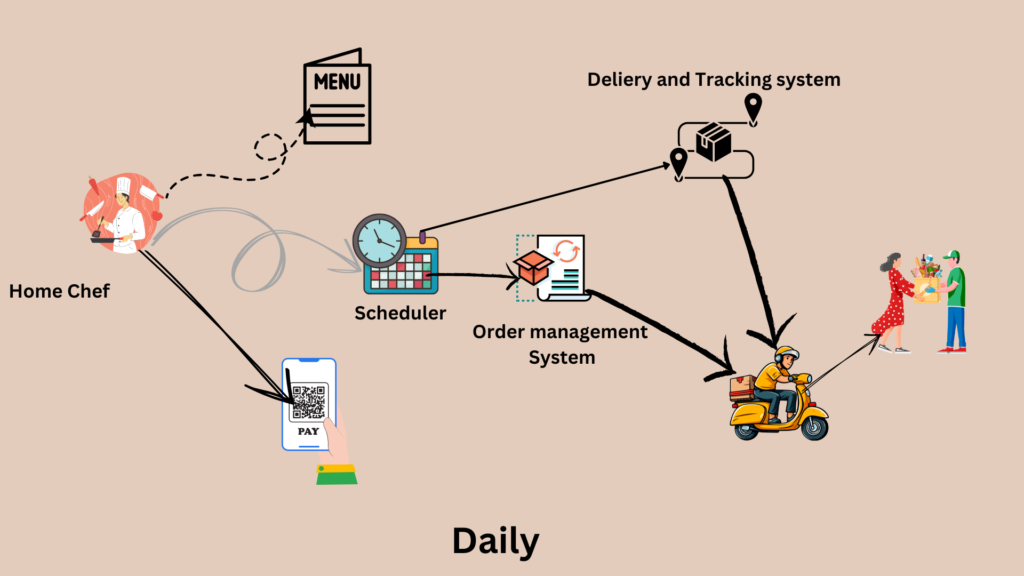
Daily provided an opportunity for people cooking food in their kitchens and not having a restaurant setup to sell on the Swiggy app. Market research found a huge demand for homemade food among customer segments that prefer healthier food with homemade taste. A new system was built to manage the supply and demand cycle of home cooks, scheduling orders and batching them as pre-orders serving breakfast, lunch, and dinner. This system was integrated with the main delivery system using the same set of delivery executives. I was the Head of Engineering for the Daily program, with a clear mandate to reuse existing systems as much as possible and build new systems where needed to enable home chefs to sell their products online. The team comprised engineers from different pods who were impacted by the Daily program
- Detailed impact analyses were performed to assess the extent of change on the existing platform due to the daily use case.
- Engineering and testing team members from each impacted POD were identified and assigned to the program.
- E2E use cases were prioritised and sequenced for implementation.
- Detailed code changes needed in existing components were identified, reviewed, and approved.
- New components and APIs were built for Home Chef onboarding, rating and review, order scheduling, payments, and app development.
- New environments and the DevOps stack were provisioned.
- New code branches and release cycles were provisioned.
- A go-to-market plan was defined along with product managers and business leads.
- A phase-wise rollout plan was created.
- Tech and business KPIs were defined and monitored.
DevOps Optimisation :
The Swiggy platform was developed based on a Java microservices architecture, with services hosted on AWS. It consisted of nearly 430 services along with a large number of RDS clusters, CI/CD pipelines, an analytics cluster, and other tools, all contributing to a significant increase in tech budget costs and a high tech-cost-to-order ratio. The objective of the project was to reduce AWS costs in line with AOV, as well as to automate features and the CI/CD process, which led to faster release cycles.
The team comprised engineers from Amazon, architects, engineers, and a testing team. A new tool called “Shuttle” was developed to automate provisioning for both software and hardware, as well as the CI/CD process and automated test execution. The tool provided an option to point to different environments, including development, UAT, integration, and pre-production.
The input to the tool was a YAML/CloudFormation template listing software packages or Docker files, the SHA of the Jenkins codebase, and configurations for the automated test suite. Upon execution, it would provision compute, memory, and I/O on a shared AWS cluster, build the tech stack, load the test data, deploy the branch, execute test cases, publish test reports, and shut down the commissioned environments—thereby significantly reducing costs
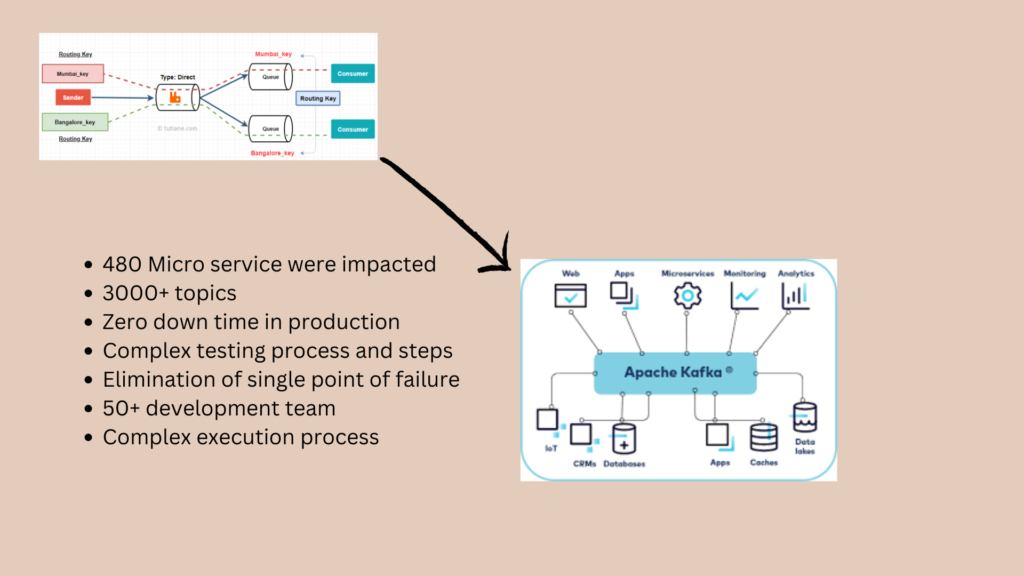
Platform microservices were using rabbit MQ inter communicating messaging layer. Rapid MQ was not stable , has issues in scalability with increase volume of messages. It was difficult to monitor and recover in case of message loss or failure. Base on the ARD review it was decided to move to new kafka based system which will predictable , measurable and observable , the other goal of the project was to document detail architecture and core design components of all pods of the platform, bring in standardisation in tech stack
1. Information about language used, API gateway , logging system , cache systems , RDS type, tools used to perform code scan, security scan, type of environment used , monitoring and alerting system used in each of 480 micro services studies and documented.
2. List of messages names , queue , message size , producers and consumers were documented
3. New Kafka clusters were provisioned to support the development
4. New customs java library was written to abstract Kafka library for future adoption
5. New producers were written to product both Kafka topic and rabbit MQ message to handle message loss during deployment or transmission phase
7. Producers changes were push to production before consumers to mitigate message loss
8. Extensive testing for message consistency, loss, fault tolerance , errors were performed to ensure 99.99% available of event layer